让大模型读懂org文件
背景
目前在 org 文件中积压的 todo 已经越来越多了,如果要完全依靠人力来回顾每一个任务、安排接下来要做的事情,可以预见这将会是一件相当花时间的事情。在通勤、上班已经占用了一天中相当大部分时间的情况下,这么做真的是太奢侈了,不如尝试将这部分工作交给 AI 来完成。
Kimi 是一个我比较常用的大模型助手,通常都是用它的网页版来进行发问。显然,我也可以通过将存放着 todo list 的 org 文件用附件的方式提交给 Kimi,让它针对其中的内容为我决策,如下图所示。

但这个做法有一些缺点,例如:
- 这个操作不自动化。需要我打开浏览器、访问网页版 Kimi、上传 programmer.txt 文件(这个文件还是我手动复制了 programmer.org 后改了后缀名的)、敲入我的提问内容(提问内容有可能是固定的),最后点击发送按钮才能开始执行;
- 这个文件中有很多不需要发送给 AI 的内容。例如,文件第一行的
#+CATEGORY、条目的 PROPERTIES、已经完成了的任务,这些都是多余的内容,浪费了 token; - 如果将来不止一个 org 文件,那么每次上传附件时需要选择的文件就会越来越多。
为此,我希望有一种办法,能将 org 文件中的核心内容提取出来,并与固定的提问内容一起发送给 Kimi。
最终效果
我希望可以仅仅是运行一个脚本,就能够输出一段文字,这段文字告诉了我接下来应当选择 todo list 中的哪一件事情来做。效果如下图所示

实现方案
要使用 Kimi 来实现前文中的截图的效果,只需要按照下图所示的流程来处理即可
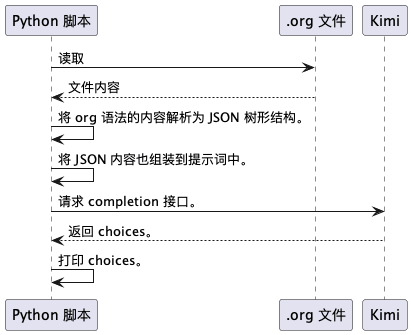
解析 org 语法的内容
一个 .org 文件中的内容可能有很多——从几 KB 到近 100 KB 不等
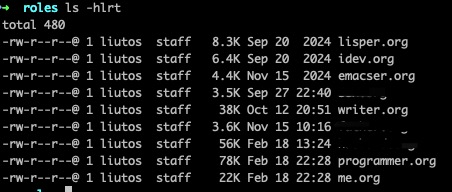
而其中的内容并非都是有意义的。例如,有一些内容是全局性的声明,如文件开头的#+CATEGORY
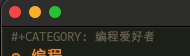
条目的PROPERTIES,以及每次计时都会新增的LOGBOOK
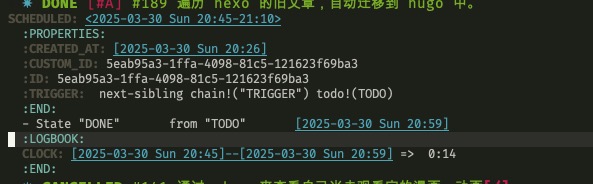
以及条目下我自己写下的笔记

我认为不需要将这些内容发送给 Kimi,因此我必须只将条目的标题从各个 .org 文件中提取出来。一个最简单的方案便是找出以星号(*)开头的行即可,示例代码如下
with open('/Users/liutos/Library/CloudStorage/Dropbox/gtd/2025/roles/programmer.org', 'r', encoding='utf-8') as f:
for line in f:
if line.startswith('*'):
print(line, end='')只是以这种方式提炼出来后的条目是扁平的,如果要做一些操作——如打乱同一层级无依赖关系的条目的顺序,就不是很好实现。因此,最好可以将 .org 文件中的条目解析为树形的 JSON 对象。在这个树形的 JSON 对象中,每一个节点的结构如下列代码所示
{
children: [], // 这个条目“下一级”的子条目,内部元素结构是递归的、与当前节点一致。
level: 0, // 当前条目的层级,即星号的数量,从 1 开始计算。
title: '', // 当前条目的标题,包含了星号的完整一行。
type: 'node' // 节点的类型,目前只有一个有效值 node。以后或许会添加 file 类型,来表示来自于不同文件的条目。
}接下来就是要设计一个算法,可以通过遍历 .org 文件中的每一行,构造出上述结构的一系列节点并连接在一起。该算法的输入为文件中的每一行组成的数组,输出为上述结构的字典组成的数组,示例代码如下
def iter_lines_and_build_tree(lines: typing.List[str]) -> typing.List[dict]:在这个算法中,声明以下两个变量
current_layer = []
parent_layer = []其中,变量current_layer将会作为最终结果在函数内return出去,此时存储的是所有一级条目的节点。这个变量之所以叫做current而不是top,是因为在遍历每一行的过程中,一旦遇到了下一级的节点,该变量的值就会被“压栈”到parent_layer中、并将值重置为当前遇到的节点组成的数组。此时,current_layer中的节点的层级就不再是顶级,而是二级、三级等,因此不给它起名叫top_layer。
而被压栈到parent_layer中的元素则是一整个完整的current_layer。当遍历到某一行的层级比current_layer[0]更高(亦即level数字更小)时,就要从parent_layer中弹栈,将“栈顶”元素赋值给变量current_layer。最终完整的函数代码如下
def iter_lines_and_build_tree(lines: typing.List[str]) -> typing.List[dict]:
current_layer = []
parent_layer = []
i = -1
while True:
i += 1 # 利用 while True 和 i += 1 的写法,可以实现在 continue 的时候自动增加计数器。
if i >= len(lines):
break
line = lines[i]
line = line.strip()
if not line:
continue
if not line.startswith('*'):
continue
line_level = line.count('*')
if not current_layer:
current_layer.append({
'children': [],
'level': line_level,
'title': line,
'type': 'node',
})
continue
current_level = current_layer[0]['level']
# 最简单的情况,就是它们是同一层级的,直接追加即可。
if line_level == current_level:
current_layer.append({
'children': [],
'level': line_level,
'title': line,
'type': 'node',
})
continue
# 其次比较简单的情况,就是新的行的缩进等级更大。
if line_level > current_level:
parent_layer.append(current_layer)
current_layer = [{
'children': [],
'level': line_level,
'title': line,
'type': 'node',
}]
continue
# 最后一种比较复杂的情况,就是同一层级的全部遍历完了,要往上级回溯了。
last_layer = parent_layer.pop()
last_layer[-1]['children'] = current_layer
current_layer = last_layer
i -= 1 # 这里减一是为了可以在回到循环开头的时候,利用 i += 1 自动又回到现在正在处理的行上。
# 如果是遍历到了最深处才退出了循环,那么要一直“出栈”直到根的那一层。
while len(parent_layer) > 0:
last_layer = parent_layer.pop()
last_layer[-1]['children'] = current_layer
current_layer = last_layer
return current_layer发送给 Kimi
成功解析了.org文件后,就需要将各个条目的内容组装到提示词中了。目前我给 Kimi 的提示词如下
question = """
以下是我的 TODO 列表:
%s
以下是其中的格式说明:
- 有一些并非真的是待办任务,而是在 org 文件中用来组织任务的“分类”,例如【验证概念】、【乐趣驱动】这种;
- TODO 是 org 格式的关键字,表示这是一个明确的待办任务。需要注意的是,即使某一行没有 TODO 关键字,也并不表示这就是不需要做的事情,只不过没有优先安排它;
- [#A] 这个表示的是任务的优先级,A 的位置可以替换为 B 或 C,优先级为 A > B > C。凡是没有这个优先级标记的,表示它们都是 B 级;
- [yyyy-mm-dd xxx HH:MM] 这种前缀表示的是条目被记录的时刻,这个是我很久之前在 org-mode 中的设定,可以忽略它;
- 后缀的 [x/y] 表示的是子任务的数量,x 是已完成的数量,y 是子任务的总数。如果 x 等于 y,则说明这个任务已经完成了,可以忽略它;
- #xxx(其中 xxx 是数字)是一个条目的“ID”,方便用来在修改了任务标题的情况下仍然可以识别到某一个任务实体;
- 每一行最左侧的连续星号表示这个分类或任务的层级,* 表示一级、** 表示二级,以此类推;
请你为我规划一下接下来我最应该做的三件事情分别是什么?在你的回答中,希望可以遵照如下的格式要求:
- 要把任务的 ID 一并告诉我,这样我才可以快速定位到具体任务;
- 不一定要按照我提供给你的优先级来安排任务,因此这些被标记为 A 级的任务有可能并非真的是最优先要处理的。如果有必要,你可以忽略 [#A];
- 相同层级的条目,它们的顺序每次都是随机的。并非靠前的任务就是优先需要完成的,请你按照 ROI 来考量并选择待办;
- 如果一个条目已经是 DONE 的状态了,就不要再推荐它;
其它要求暂时没有。
""" % ('\n'.join(todo_list),)其中,变量todo_list就是通过遍历函数iter_lines_and_build_tree的返回值来构建的、扁平的条目数组。构造了提示词后,利用第三方库openai将内容发送给 Kimi 即可,示例代码如下
system_content = """
你是一个时间管理大师,擅长为别人规划任务。
"""
completion = client.chat.completions.create(
model="kimi-k2-turbo-preview",
messages=[
{"role": "system",
"content": system_content},
{"role": "user", "content": question}
],
temperature=0.6,
)最后再输出completion.choices[0].message.content即可。
全文完。