读取 JSON 配置文件
序言
在前一篇文章中,连接数据库的配置是写在代码中的,在谓词url_to_id中重复出现了两次。在本文中,会将配置从源文件中剥离出来,改为在程序启动的时候从 JSON 格式的配置文件中读取。
配置文件及其解析
新增一个配置文件config.json,其内容如下:
{
"mysql": {
"dsn": "DRIVER={/usr/local/mysql-connector-odbc-8.0.33-macos13-x86-64bit/lib/libmyodbc8a.so};String Types=Unicode;password=1234567;port=3306;server=localhost;user=shorten"
}
}接着新增一个源文件config.pl,它负责实现一个用于解析 JSON 文件的模块
:- module(config, [current_dsn/1, parse/1]).
:- dynamic current_dsn/1. % 声明一个动态谓词,用于存储解析好的 ODBC DSN 字符串。
:- use_module(library(http/json), [atom_json_dict/3]).
:- use_module(library(readutil), [read_file_to_string/3]).
parse(ConfigPath) :-
read_file_to_string(ConfigPath, String, []),
% 按照 JSON 格式反序列化为字典类型的数据。
atom_json_dict(String, JSONDict, []),
% 将 DSN 字符串存储在谓词中,这样外部就可以通过 current_dsn/1 获取。
asserta(current_dsn(JSONDict.mysql.dsn)).使用效果如下图所示
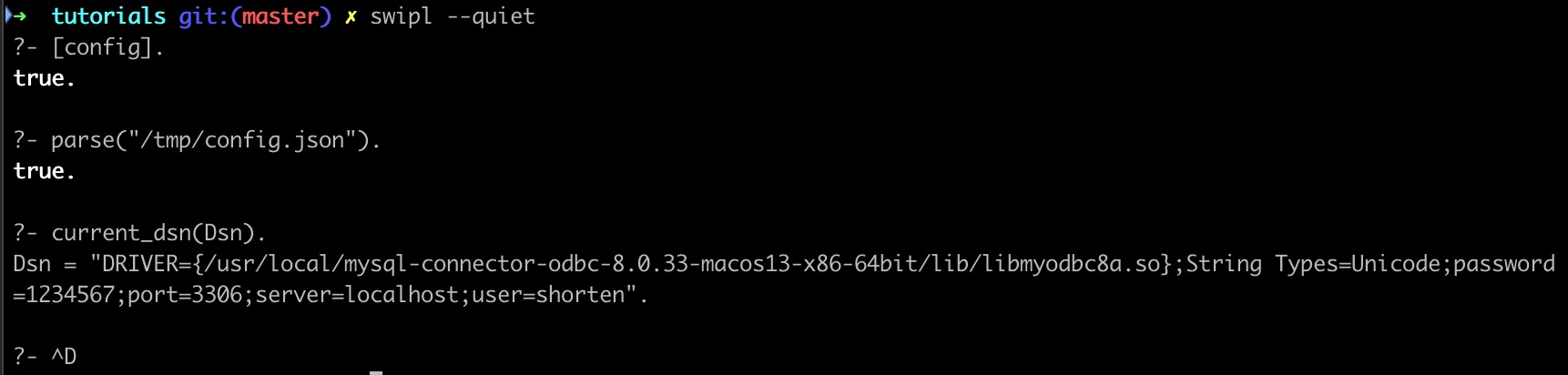
现在可以改写源文件http_server.pl和url_to_id.pl了,前者在谓词main中调用parse/1来解析配置文件,后者调用current_dsn/1来获取 DSN 以连接数据库。
字典类型
在parse中调用atom_json_dict得到的JSONDict是一个字典类型的对象,可以用write来查看它的内容
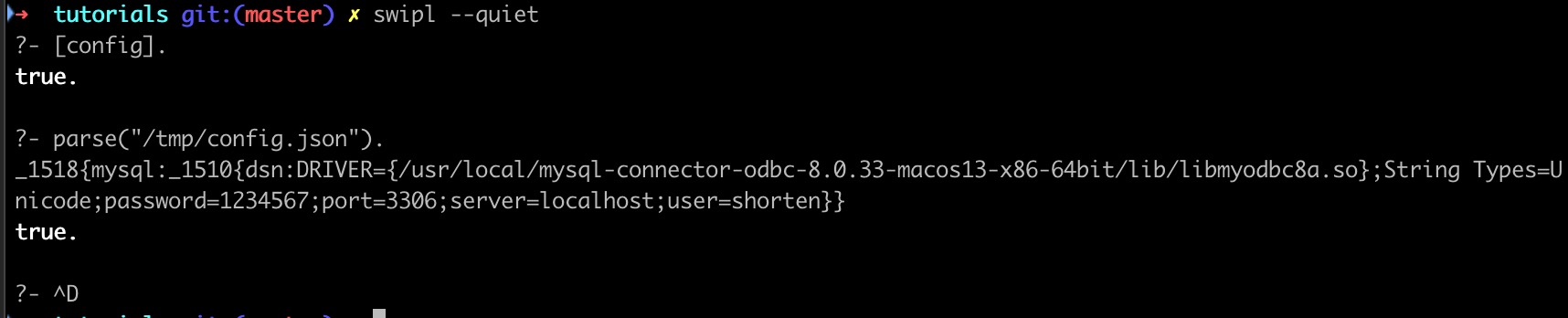
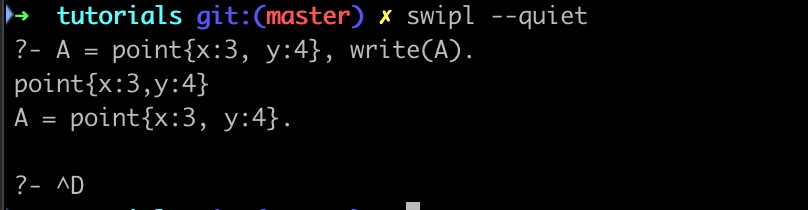
图中如_1518、_1510这样的项在 SWI-Prolog 中叫做Tag,可以将其视为系统随机生成的类型名,而如mysql、dsn这样的位于冒号左侧的就是字典的键、右侧的就是对应的值。这个语法也可以用于输入字典字面量
命令行选项
尽管在前文中,ODBC DSN 已经被放到了配置文件中,但是配置文件的路径仍然是写在源文件中的(节选如下)
main(_) :-
% 解析配置文件。
parse("./config.json"),一个更好的做法是将配置文件的路径通过命令行选项传给程序,为此这里用到了谓词opt_arguments来解析命令行选项。新增一个模块cli_parser.pl来负责解析命令行选项
:- module(cli_parser, [extract_config_path/2, parse_argv/1]).
:- use_module(library(optparse), [opt_arguments/3]).
extract_config_path([], _) :- fail.
extract_config_path([config_path(ConfigPath) | _], ConfigPath).
extract_config_path([_ | Opts], ConfigPath) :- extract_config_path(Opts, ConfigPath).
parse_argv(Opts) :-
OptsSpec = [
[
opt(config_path), % opt_arguments 要求每个命令行选项都必须指定 opt。
shortflags([c]), % 短的选项名称,使用时为 -c。
type(atom) % 传入的值为字符串,因此必须指定类型为 atom。
]
],
opt_arguments(OptsSpec, Opts, _).要测试这个模块,可以在启动swipl时输入两个连字符--,然后再跟着要被解析的命令行选项,如-c '/Users/liutos/Projects/shorten/tutorials/config.json'。这样一来,--之后的部分都将可以被opt_arguments处理到,如下图所示

最后在谓词main中调用这两个新的功能即可
main(_) :-
% 解析命令行选项。
parse_argv(Opts),
% 取出配置文件路径。
extract_config_path(Opts, ConfigPath),
% 解析配置文件。
parse(ConfigPath),
http_handler('/api/lengthen', lengthen_url, [methods([get])]),
http_handler('/api/shorten', shorten_url, [methods([post])]),
http_server([port(8082)]),
sleep(100000000).模式匹配和递归
由于谓词opt_arguments将命令行选项的解析结果以列表、而不是字典的类型存储到变量Opts中,因此如果要从中取出配置文件的路径,就需要遍历Opts。在主流语言中,这通常使用某种循环语法来实现。例如,在 Python 中,代码可能是下面这样的
# -*- coding: utf8 -*-
def extract_config_path(opts):
for opt in opts:
if opt[0] == 'config_path':
return opt
raise Exception('找不到配置文件路径。')
def main():
"""遍历一个元组的列表来找出配置文件路径。"""
opts = [
('config_path', '/Users/liutos/Projects/shorten/tutorials/config.json'),
]
opt = extract_config_path(opts)
print('opt', opt)
if __name__ == '__main__':
main()而在 Prolog 中,通常会用模式匹配和递归来实现。例如,在谓词extract_config_path的三种定义中,第一种的参数分别为[]和_,其中[]表示空列表,而_可以认为表示“不管是什么值”。这个定义的含义是:只要第一个参数为空列表,则extract_config_path总是无法成立——这是对的,因为空列表中无法取出有效的配置。
第二种定义中,第一个参数为[config_path(ConfigPath) | _],它是列表字面量的语法,其中config_path(ConfigPath)是表头,剩下的元素都是表尾,由_承载——也就代表它们并不重要。表头config_path(ConfigPath)是一个“模式”,它表示这里的值是一个复合项(compound term),其中原子config_path叫做函子(functor),变量ConfigPath属于它的参数。第二个表达式没有:-及其右边的表达式,也就意味着只要查询的语句符合这个结构,那么就总是成立的,它的含义是:只要第一个参数(是个列表)的表头是一个以config_path为函子的复合项、并且它的唯一一个参数与第二个参数相同,那么这个查询就成立。
如果一个列表既不是空的、它的表头也不符合模式config_path(_),那该怎么办呢?这时候应当继续遍历列表的表尾,看能否最终找到符合要求的元素,也就是第三个定义所做的事情。它将第一个参数的表尾存储在变量Opts中,并以它为新的第一个参数、递归地调用了自身。它的含义是:如果前两个定义都无法使查询成立,那么将会以相同的方式处理表尾。只要能够在表尾中找到了配置文件路径,那么当前的查询也是成立的。